

When Delta’s data center blacked out in the summer of 2016, it led to three days of canceled flights and nine figures of lost revenue.
Since we’re concerned with all things uptime at Blue Matador, we’ve been tracking major IT outages in 2017 and quantifying their effects on the companies and customers involved.
It isn’t pretty. But there’s always lessons to be learned. What caused the downtime? How long did it last? How could it have been prevented? Let’s take a look at 2017’s best (worst?) downtime incidents.
Lowe’s Retail Website Busts for 21 Minutes on Black Friday
 Mobile shopping makes up more than half of all B2C transactions in the U.S. So when Lowes’ website went down on Black Friday, they stood to lose a lot more than potential sales. Black Friday, part of what analysts are now calling “Cyber Week”, isn’t the best day for your commercial website to crash.
Mobile shopping makes up more than half of all B2C transactions in the U.S. So when Lowes’ website went down on Black Friday, they stood to lose a lot more than potential sales. Black Friday, part of what analysts are now calling “Cyber Week”, isn’t the best day for your commercial website to crash.
Based on their approximate downtime of just 21 minutes, we extrapolated their lost revenue to be around $2.4 million. Their stock price also took a dip of 2.9% over a 24-hour period, with trade volume decreasing 78.4% in a single day. (If you’re not stock savvy, just know that that’s really bad.)
What went wrong? Lowe's didn't allocate or rebalance enough servers to handle the increased load Black Friday caused on their systems. They could have set up redundant CDNs or added more virtual servers to their infrastructure for the week.
Macy’s Payment Processing Takes a Break for 6 Hours
 Lowes wasn’t the only brick and mortar store to be hit with a huge outage on Black Friday. Merchandisers like Macy’s rely on payment processors to handle their point-of-sale transactions. So when a processor goes down, shoppers take their cash elsewhere and stop giving positive recommendations to friends.
Lowes wasn’t the only brick and mortar store to be hit with a huge outage on Black Friday. Merchandisers like Macy’s rely on payment processors to handle their point-of-sale transactions. So when a processor goes down, shoppers take their cash elsewhere and stop giving positive recommendations to friends.
Some 61,785 customers were affected across their 700+ locations. Extrapolated, this was approximately $18.5 million in lost revenue for the department store.
What went wrong? Macy's handles its own payment processing, so it wasn't caused by a third-party processor. They knew that Black Friday would strain their website since 2016 had similar problems for the beleaguered department store. But they didn't anticipate the load on their payment servers, even as more and more Americans are paying with credit cards for everyday spending.
Slacking: Where Work (Didn't) Happen for 2.5 Hours on Halloween Day
 We rely on business productivity app Slack to communicate across teams and projects here at Blue Matador. Like other companies, SaaS users rely on their cloud services to be productive. But when cloud apps experience outages, angry customers go online to complain.
We rely on business productivity app Slack to communicate across teams and projects here at Blue Matador. Like other companies, SaaS users rely on their cloud services to be productive. But when cloud apps experience outages, angry customers go online to complain.
When Slack went down at the beginning of the work day in the Eastern hemisphere, some 1,402 customers reported downtime within an hour. An estimated 6 million Slack users were affected, or about two-thirds of their user base.
That's a lot of missed messages. Based on Slack's annual revenue and the amount of downtime incurred, we estimated they lost about $1.12 million from the Halloween hiccup.
What went wrong? Slack said it was "routine internal deployment of software to our servers" that caused everyone to be disconnected and then unable to reconnect. "Routine internal deployment" is another way of saying server maintenance, and maintenance is a common task for engineering teams to maintain uptime. Although Slack never revealed exactly what caused their deployment to replicate downtime across their infrastructure, it's likely they experienced an internal problem similar to the one we're about to describe below...
World’s Largest Cloud Provider Fails for 5 Hours, Universe Stands Still
 In February, one of Amazon’s largest outages occurred — for over 5 hours. Since the internet is built on the backbone of content delivery networks and cloud storage providers, when a big player like AWS goes down, even the best AWS monitoring service isn't going to help.
In February, one of Amazon’s largest outages occurred — for over 5 hours. Since the internet is built on the backbone of content delivery networks and cloud storage providers, when a big player like AWS goes down, even the best AWS monitoring service isn't going to help.
Some 148,000 hosted customers were affected, and, when you count the visitors of those websites, the number affected expands exponentially.
The ultimate irony, however, came when DevOps admins who were glued to the AWS status page noticed that "Amazon couldn't get into its own dashboard to warn the world" because the green, yellow, and red status icons were hosted on servers affected by the outage.
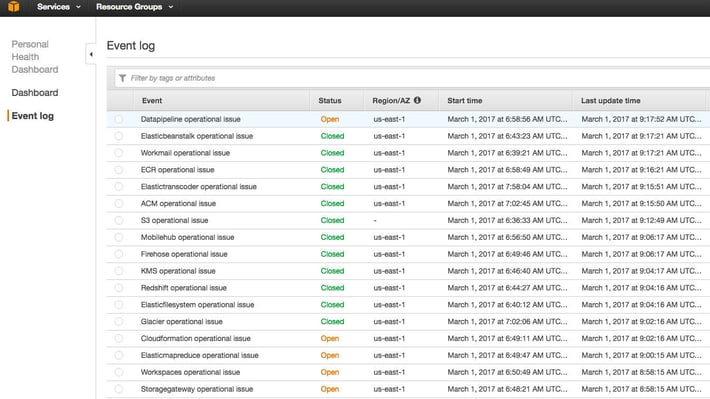
The Register reported a list of some of the most popular sites and services affected:
Docker's Registry Hub, Trello, Travis CI, GitHub and GitLab, Quora, Medium, Signal, Slack, Imgur, Twitch.tv, Razer, heaps of publications that stored images and other media in S3, Adobe's cloud, Zendesk, Heroku, Coursera, Bitbucket, Autodesk's cloud, Twilio, Mailchimp, Citrix, Expedia, Flipboard, and Yahoo! Mail (which you probably shouldn't be using anyway). Readers also reported that Zoom.us and some Salesforce.com services were having problems, as were Xero, SiriusXM, and Strava.
As a result, people started noticing weird things happening, especially with IoT connected devices. One user's day seemed particularly affected:
Joys of the @internetofshit - AWS goes down. So does my TV remote, my light controller, even my front gate. Yay for 2017.
— Brian (@Hamster_Brian) February 28, 2017
Additionally, DownDetector and IsItDownRightNow.com, two sites used for checking downtime, went down themselves. The Register noted that it wasn't clear if AWS affected those sites directly, or if the sheer number of people checking for outages caused them to go down. But the result was clear: On February 28, 2017, the internet essentially broke.
What went wrong? Amazon said the problem was caused by a console typo, a typo that brought down more servers for maintenance than intended. This cascaded into additional problems for nodes that relied on those servers for operational efficiency, which in turn caused #Amazongeddon: servers all across the US-EAST-1 region started to fail. Amazon S3 console, Amazon Elastic Compute Cloud (EC2), new instance launches, Amazon Elastic Block Store (EBS), and Lambda were all affected.
Playstation Network and Nintendo Switch Eshop: Errors Here, Error There, Just Errors Everywhere
 As many around the world unwrapped their new PS4 or Switch consoles on Christmas Day, they weren’t able to connect them to their respective networks. The PSN Network and Nintendo eShop both had connectivity issues on Christmas day. And gamers (or little gamers' fathers) were upset.
As many around the world unwrapped their new PS4 or Switch consoles on Christmas Day, they weren’t able to connect them to their respective networks. The PSN Network and Nintendo eShop both had connectivity issues on Christmas day. And gamers (or little gamers' fathers) were upset.
Dude PSN is annoying already. Every time I try and do something I get an error. Error here error there just errors everywhere. Website and console. @PlayStation
— JR (@GunnersAlive) December 25, 2017
This is not the kind of tweet you want your home console brand to be receiving on Christmas day from a new customer. Sony Interactive Entertainment engineers assigned to the PlayStation Network likely didn’t have a good Christmas day as a result. Even the servers responsible for redeeming game vouchers was down.
We're aware that some users are having issues redeeming vouchers on PSN. Thank you for your patience as we investigate. Please be sure to follow us for further news and updates.
— Ask PlayStation (@AskPlayStation) December 25, 2017
What went wrong? Both Sony and Nintendo didn't allocate enough server bandwidth to handle a single-day usage spike. Like Amazon's cascading server problems mentioned above, the PSN and eShop had further issues down the line caused by problems with dependent servers going down first.
Downtime can be prevented. But you need the right monitoring tools. While most monitoring programs focus on visualizations, Blue Matador actually sends you predictive alerts ahead of time making sure you'll be the first to see problems before anyone else.


