

When the customer support reps at your company think of “downtime,” they’re probably not thinking of “reduced activity or inactivity”. Instead, they probably think of stressful barrages of support calls and exploding social media accounts resulting from your app’s service interruptions.
Server outages, while difficult challenges for executives and DevOps engineers, are just as awful for support agents to deal with. As the public-facing employees of the company to its customers, support reps bear the brunt of outages when it comes to customer interactions.
And there are lasting detriments to customer trust that are made or broken by how support reps communicate with customers during outage crises. This compounds into frustration and burnout for support reps, who have little to no control over downtime themselves.
“If people like you, they’ll listen to you. But if they trust you, they’ll do business with you.” –Zig Ziglar, American author, salesman, and motivational speaker
The customer support team has to deal with service interruption aftermath as well, such as conducting retrospective investigation for customers or fixing problems resulting from outages. They might even have to navigate customer requests for refunds or discounts that inevitably come after longer periods of server downtime, especially if customers are closely watching contractual or advertised SLAs.
“Far too many people think it's okay to take their frustrations out on a support rep, whether they're related to the [downtime event] or not” –Len Markidan, Zapier
Communicate with Customers — Communicate Quickly
When it comes to company disasters in general, transparency — not translucency — is the key to mitigating customer backlash. For companies that use a popular service like AWS, you could point to their status page if the outage is a system failure beyond your control. In the case of an instance failure, you can learn your lesson and invest in AWS application monitoring. Regardless of where the point of failure is, you should immediately disclose service issues because it goes a long way to quell customer concerns and support tickets.
Because customers will reach out through social channels as well as support ones, it’s important to continually keep customer service reps educated on the status of the outage.
“System downtime can hit any online business at any time. And the way you find out about disruptions – a barrage of tweets, emails or chats – isn’t a nice experience.” Adam Rogers, Kayako
Atlassian, no stranger to status updates, recommends a dedicated communicator as a go-between for the engineering team responsible for maintaining uptime and the support team handling damage control. However, if you’re in a small-to-medium business, you likely won’t have resources for a dedicated rep. So creating a playbook for communicating downtime ahead of time (awkward alliteration intended) can be an effective in preparing support agents.
The playbook should start with an apology from highest up in the company if possible: the CTO, the CEO, or the president.
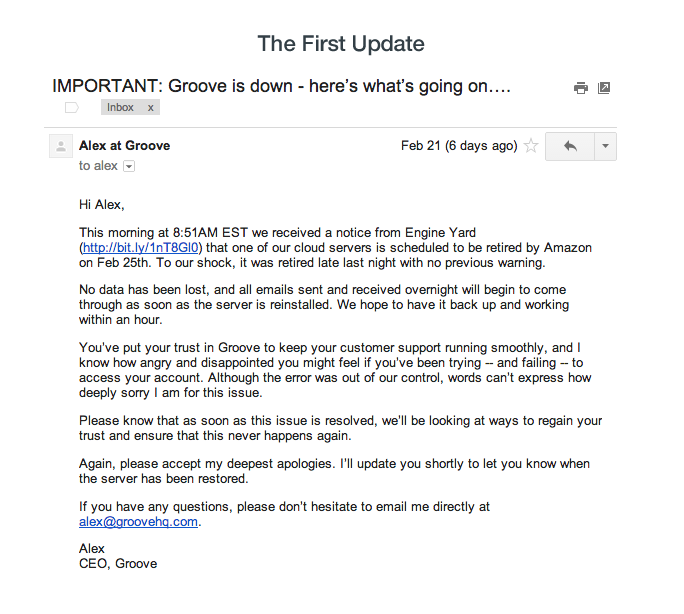
Email. An email like this one from support desk software Groove (original post here) is a great way to push an alert out to your customers before they might notice and call in to question the support team.
Blog. Writing a quick blog post (especially if the email links to it) is a helpful, permanent place for a downtime announcement to exist. (We say permanent because, again, it helps with transparency, and having a future 404 that’s linked to from official channels doesn’t help).
When writing the post, you don’t need to make it an epic press release. Simply communicate the problem and your sense of urgency and give it a permanent place on your site. Here’s an example from landing page maker Unbounce. As you’ll see, it was written by their CTO, an engineer who’s pretty high up there as far as perceived responsibility in customers’ eyes.
Status Page. Publishing a bookmarkable status page highlighting all your systems is another good way to redirect a lot of concerned customers’ inquiries to support. Fortunately, creating such a page is relatively easy. There are status board services like Atlassian’s StatusPage or custom solutions like Amazon’s AWS Service Health Dashboard.
Composing a series of tweets that update outage statuses every half hour or on the hour is also a quick and simple way to communicate downtime to your most social customers (or to the media who may be covering it).
“When things go awry, your customers want to know that you're on top of things, and that there's nothing in the world more important to you than fixing whatever is broken.” –Len Markidan, Zapier
Last, a catch-all way to handle all the rest of the inquiries about your service interruption is an alert bar of some kind on your website. Your site is likely the first place customers will go when they notice uptime issues with your software. BugMeBar is a popular WordPress plugin that can accomplish this.

If all of this communication sounds scary to you, remember, the fact is most people will forgive you and forget the downtime if you’re honest and up front. If Bill Clinton can go on and recover from the Lewinsky scandal, so can your app from a moment of unplanned downtime.

The alternative to communicating a negative event is like what one major retailer did when it experienced credit card processing issues on Black Friday in 2017. When Macy’s credit card processing failed on Black Friday, they didn’t notify customers, and they got angry.
Fix Downtime Fast
Now that you’ve handled communication channels to help your support reps handle a more manageable level of inquiries, you can focus on fixing the downtime.
Of course, server monitoring tools should be integral in your strategy to alleviate downtime. There’s a ton of software options out there — some paid, some open source — and they’re all better to use than nothing for keeping tabs on your infrastructure’s uptime.
Popular tools include Zabbix, Nagios, Prometheus (all open source), and DataDog (paid). We make our own free tool called Watchdog, which is a quick install and effective alternative to open source offerings.
Centralizing all of your system logs into one system that can alert on anomalies or thresholds will also go a long way to speeding up your mean time to resolution (MTTR). A lower MTTR means owntime’s effects on customers and your support reps is minimized.
Centralized log management is crucial to your downtime prevention strategy because it helps your engineering team triangulate the root cause and fix the problem faster. This is usually helpful because alerts are generated from algorithmic log file analysis. The alternative to centralized logging is manually grepping your journald collections or combing your Windows event logs — neither is a fun or time-considerate thing to do in a moment of crisis.
Speaking of alerts, here’s a protip to get more use out of your monitoring and logging tools: Assign your customer support reps user seats in the software. Not only can you directly send them alerts the moment a problem is noticed, but also they can log in to check on downtime events themselves. This results in more insightful and relevant answers for concerned customers’ questions about service interruptions
There’s A Better Way — Downtime Prevention
Now that you’ve successfully mitigated lack of trust among your customers in a moment of company downtime, and fixed the problem, it might be worth it for your support team to prevent downtime altogether.
Instead of remediation happening on the backend of the problem, you can fix it on the frontend before it strikes. If you’ve been directly involved in fixing downtime yourself, you’re probably used to the paradigm that you only receive alerts after an anomaly has already occured.
Instead, look for a monitoring tool or log management software that is powered by artificial intelligence and notifies with predictive alerts — alerts that look for patterns in data even when you’re not logged in and searching.
You’re probably also used to alerts that require manual tweaking and constant threshold-tuning to avoid false positives and negatives. Our logging solution, Lumberjack, learns growth, decay, and seasonality to fine-tune thresholds on the fly. The result is 15 minutes of advanced warning before a service interruption occurs — plenty of time for you or your engineering team to mitigate, remediate, or rebalance. That way, your customers (and your customer support team) aren’t affected in the first place.
Downtime Doesn’t Have to Kill Your Customer Support Team
The net result of all your efforts here is to let customer support do their real job (the one that will make them feel productive): Improve customer satisfaction by helping customers with billing or technical support issues.



{kind=link}