
You work in DevOps. You live DevOps. Perhaps DevOps is even in your job title. But do you know the origins of the term — and more importantly — where the industry is going?
Learning about the history behind cloud server monitoring is important because it helps us learn from past mistakes (and avoid repeating them) and to help us better predict where the future is going. Here’s a cursory look at the history of the DevOps methodology and where your favorite software tools may fit into its future.
The Origins of the Developer
You can’t talk about developers without talking about computers first. Computers have been around for longer than you probably have. The concept of a computer has origins in Alan Turing’s idea for an “automatic machine” in 1936. As an analog device, the idea behind the Turing machine was to read tables of finite data using tapes and mechanical computation.
Turing’s idea led to the creation of electromechanical computers used to help the U.S. government decipher enemy encryption in WWII. These early computers led the way to later, larger mainframes created with vacuum tubes, the kind of hardware you might see in old sci-fi movies with dozens of dials and blinking lights.
For as long as these computing devices have existed, there has been a need for operators to program them to do something. The first developers, as you might think of them in a modern sense (sitting down at a terminal and writing stored, digital code) came about with the creation of the Fortran programming language in 1957.
By the late 1970s and 1980s, when CRT monitors became increasingly affordable, developers could regularly sit at their workstation, write code in development, compile it, and test it on the same computer. Deploying code consisted of compiling, copying to dozens of flop disks, and repeating. Companies started advertising for programming positions to write “source code,” a term that had only recently entered the lexicon.
There were few developers, however, working in network engineering, because the internet had not yet been invented. The idea of “uptime” and “downtime” was generally limited to whether a computer was turned on or off, unless you were one of the few terminals connected to what would later become the origins of the internet.
ARPANET, the Internet, and the Creation of the “Site Reliability Engineer”
Before the World Wide Web, there was ARPANET, a government-sponsored network of computers across the United States that interconnected using packet switching over telephone lines. ARPANET went live in 1969, creating the first rudimentary “network operations centers” across the country, with “ops” personnel managing the network’s configuration and uptime.
Fast-forward past 1989 — after Tim Berners-Lee had created the first World Wide Web protocol, HTTP — to when Google, in 2003, hired Ben Treynor to lead engineers in a “production environment,” separate from the “development environment.” These engineers’ new job titles became history: site reliability engineers, or SREs for short.
‘Fundamentally, it’s what happens when you ask a software engineer to design an operations function.’ –Ben Treynor on site reliability engineering
Their task was to maintain high uptime for Google, working with developers to ensure operations didn’t break for customers. After all, any downtime Google experienced in its main product, Search, resulted in thousands of dollars of lost revenue from AdWords, which launched in 2000. Though the term hadn’t been coined yet, SREs were the first real “DevOps” practitioners.
Flickr Begins to Combine “Dev” + “Ops”
Google wasn’t the only company to start employing SREs. Soon, all the big tech players began to implement site reliability philosophies to reduce downtime and increase customer satisfaction. In 2008, Apple’s MobileMe experienced significant downtime in which the nascent cloud service received “a lot more traffic to [their] servers than [they] anticipated,” proving that even big tech wasn’t immune to downtime — or angry customers.
‘It’s not my machines, it’s your code!’ vs. ‘It’s not my code, it’s your machines!’
Enter John Allspaw and Paul Hammond, Flickr engineers. Through their experience managing uptime at the world’s largest photo-sharing site (at the time), Allspaw and Hammond noted that the ops team, charged with managing servers, and the dev team, tasked with creating code, seemed to always be at odds (or “fingerpointy”) with each other.
The solution, they proposed, was to hire “ops who think like devs” and “devs who think like ops.” In a presentation at the 2009 O’Reilly Velocity Conference, Allspaw and Hammond proposed integrating development and operations into an automated infrastructure with shared version control and one-step build and deployment. “DevOps” was born. But it didn’t have a name. Yet.
Belgium: The First DevOpsDays
An engineer named Patrick Debois from Belgium, unable to attend the O’Reilly conference in San Jose, California, decided to organize his own smaller conference concerning “agile system administration.” Looking to advertise the conference on Twitter, Debois creates the portmanteau “DevOps” as a shortened hashtag from development and operations. The hashtag quickly becomes the name of the movement that Allspaw and Hammond first articulated at the Velocity conference.
Not only did Debois’ name for agile system administration stick, but also did his model for localized, quick “DevOpsDays” as well. Today, DevOpsDays is a worldwide movement where developers and operations professionals get together in their host countries to discuss automation, testing, security, and the organizational culture needed to avoid pitting dev and ops against each other.
Google Trends data showing the rise of “DevOps” in search. Note the growth from 2009 to present.
Modern DevOps and the “Franken-monitor”
Given that “DevOps” as a methodology is still relatively new, it may be considered a misnomer to talk about “modern” DevOps. However, this is the tech world we are talking about, and things move swiftly here. In 2013, Bernd Harzog, then an APM analyst at The Virtualization Practice, blogged about the “Fanken-monitor” effect. He lamented that the current state of DevOps monitoring consisted of duct-taping together a hodgepodge of monitoring tools in order to create a complete picture of a given infrastructure.
‘It’s not my machines, it’s your code!’ vs. ‘It’s not my code, it’s your machines!’
We’ve written about the Franken-monitor here on this blog, and our CEO has presented on the topic. And we think it’s a major problem. That’s why we launched our Blue Matador DevOps monitoring platform, where we intend to have a software monitoring product for each aspect of the development and operations cycle. We think this approach will solve a lot of problems for organizations that have built their own Frank-monitors, only to find out they are costly, clunky, and reactive instead of proactive and predictive of downtime.
DevOps: Fad or Future?
A brief history of DevOps wouldn’t be complete without a quick glance at the future. Knowing where DevOps has been in the past decade, where can we see the industry moving?
From a dollars and cents perspective, DevOps will continue to boom. According to a recent Technavio research report, the global DevOps market will experience a 19.42% CAGR from 2016–2020. (For the uninitiated, CAGR is compound annual growth rate, and anything between 10–20% is very good for investment prospects.)
In short, DevOps is here to stay for the foreseeable future until some new methodology — or technology — comes along to disrupt the space. After all, that’s what DevOps is already doing to the standalone practices of development, operations, QA, and security.
We’re already seeing signs of DevOps maturing and evolving into something more. Artificial intelligence is starting to permeate everything from smartphones to self-driving cars. It will also help disrupt DevOps’ mantra to “automate, automate, automate” as well. (We believe in the benefits of adding AI to monitoring software so much so that we already implemented it into our shared Smart Agent to provide predictive log and server metric alerts.) For example, CIO magazine recently reported that virtual assistants are “fueling adoption” of ChatOps and VoiceOps. Expect to see more bots and other AI-powered aspects of DevOps in the near future.
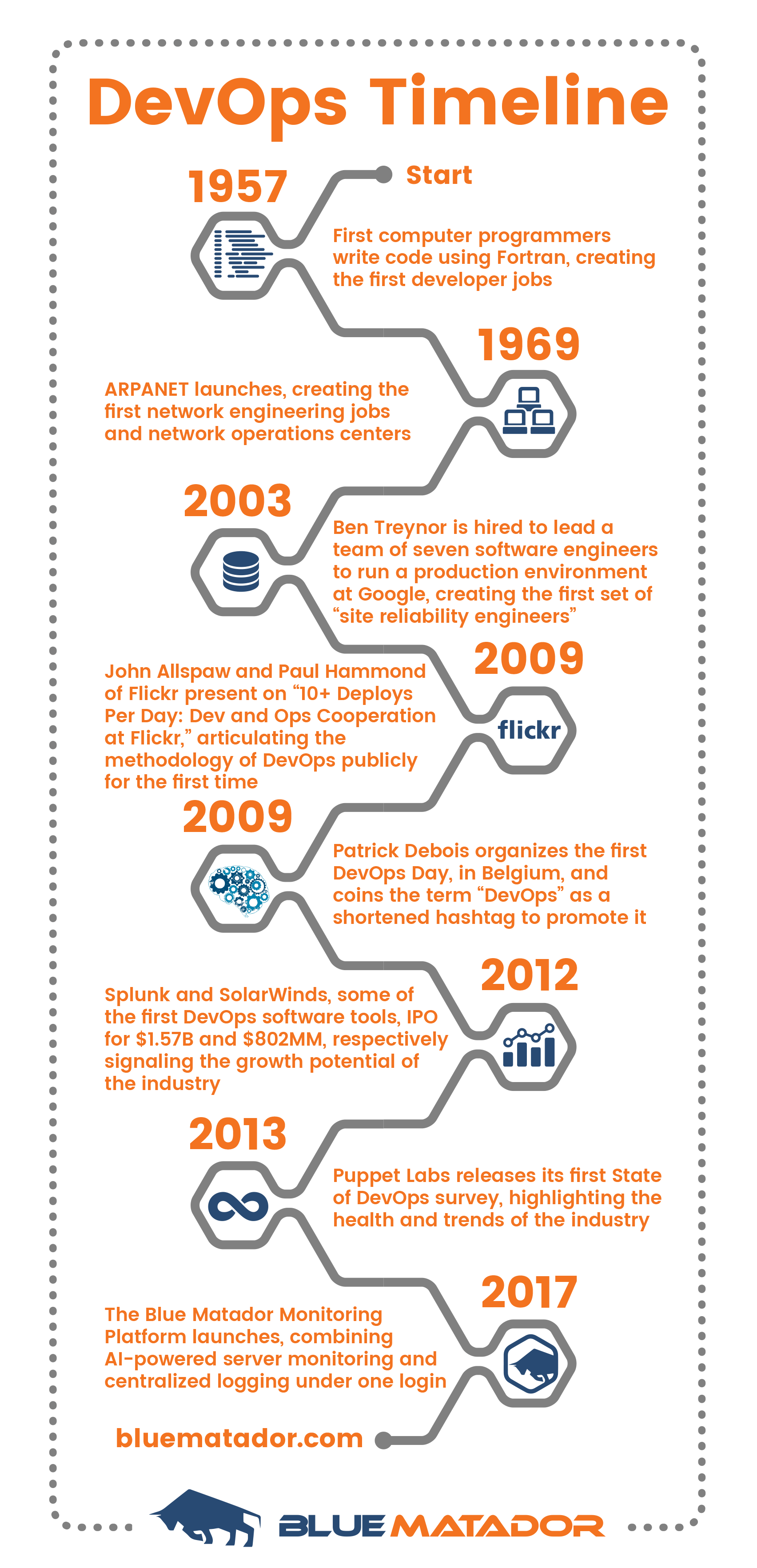
Timeline of Key DevOps Events
1957 – First computer programmers write code using Fortran, creating the first developer jobs
1969 – ARPANET launches, creating the first network engineering jobs and network operations centers
2003 – Ben Treynor is hired to lead a team of seven software engineers to run a production environment at Google, creating the first set of “site reliability engineers”
2009 – John Allspaw and Paul Hammond of Flickr present on “10+ Deploys Per Day: Dev and Ops Cooperation at Flickr,” articulating the methodology of DevOps publicly for the first time
2009 – Patrick Debois organizes the first DevOps Day, in Belgium, and coins the term “DevOps” as a shortened hashtag to promote it
2012 – Splunk and SolarWinds, some of the first DevOps software tools, IPO for $1.57B and $802MM, respectively signaling the growth potential of the industry
2013 – Puppet Labs releases its first State of DevOps survey, highlighting the health and trends of the industry
2017 – The Blue Matador Monitoring Platform launches, combining AI-powered server monitoring and centralized logging under one login


